How to dramatically improve the reasoning ability of GPT-3
Following up on my recent post about prompt engineering, in this post I explore a technique that dramatically improves GPT-3’s reasoning ability and output quality. Presumably, this will work on other large language models (LLMs) as well.
Somewhat unsurprisingly, this technique is the same one you’d ask a student to use when solving a problem: show their work.
Asking GPT-3 to show its work
Let’s look at an example prompt:
For each example, decide if it's a good product to sell to a startup:
Product: Global office space management platform.
Good for startups: No
Product: Ticket management platform for in-house legal team.
Good for startups: No
Product: Recruiting and interviewing CRM platform.
Good for startups: Yes
Product: Website copy optimization tool.
Good for startups: Yes
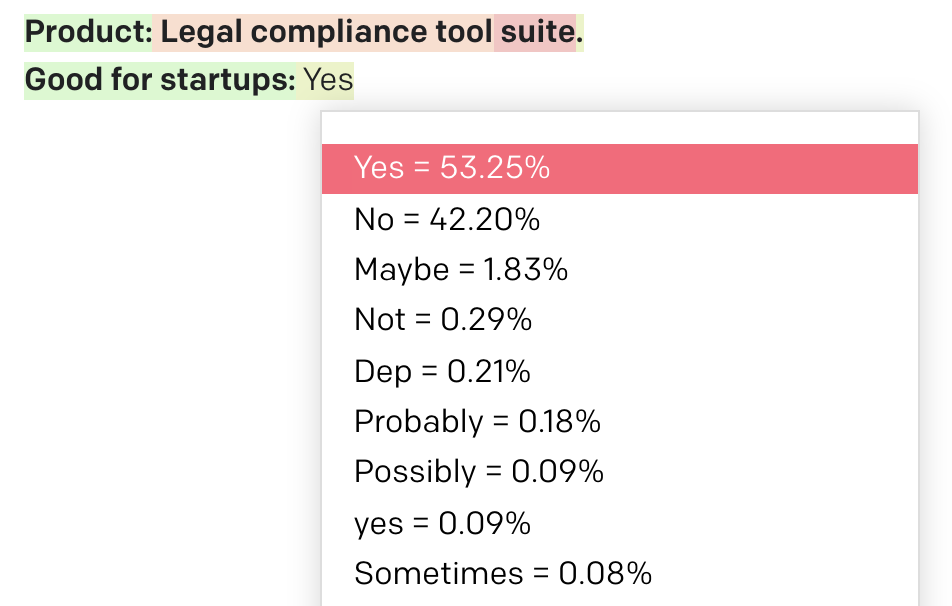
Product: Legal compliance tool suite.
Good for startups:
GPT-3 on Davinci (the largest model) with low temperature generates Yes, which I personally think is incorrect. Looking at the logprobs, it predicted Yes at 53.25% and No at 42.20%.
Now, let’s try the same few-shot prompt, but this time asking for the model to show its work:
For each example, decide if it's a good product to sell to a startup:
Product: Global office space management platform.
Reasoning: Startups are small, they don't have global office space to manage.
Good for startups: No
Product: Ticket management platform for in-house legal team.
Reasoning: Startups are usually too small to have an in-house legal team.
Good for startups: No
Product: Recruiting and interviewing CRM platform.
Reasoning: Startups do a lot of recruiting and interviewing.
Good for startups: Yes
Product: Website copy optimization tool.
Reasoning: Startups are focused on growth and need to optimize their websites.
Good for startups: Yes
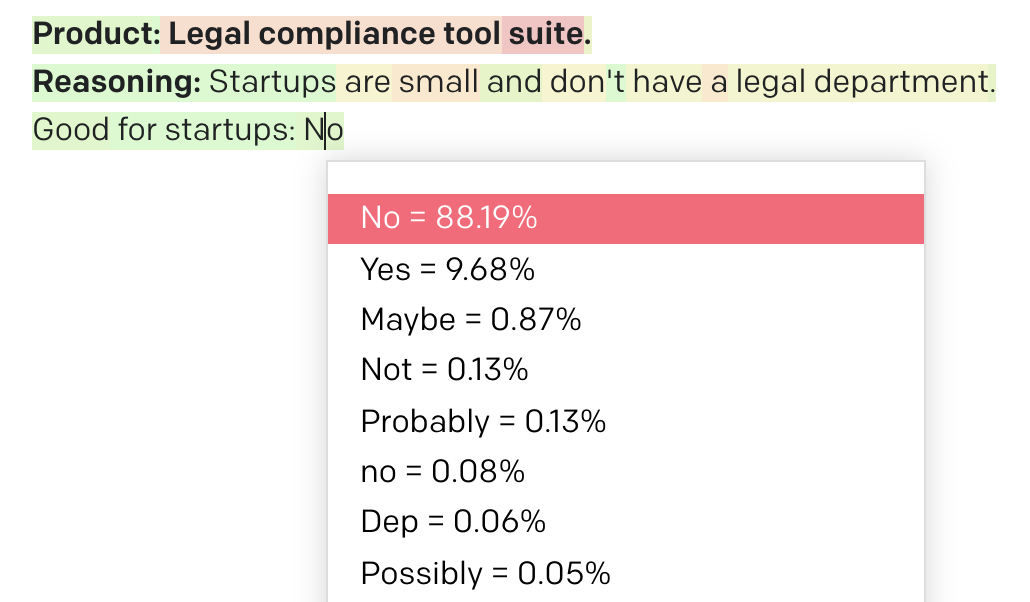
Product: Legal compliance tool suite.
Reasoning:
GPT-3 outputs a reason of Startups are small and don't have a legal department. and a conclusion of No. Nice!
This time the logprobs were No at 88.19% and Yes at 9.68%.
Another example
Was this a fluke? Let’s try another example.
Classify each sentence as logically correct or incorrect.
Sentence: Dogs are a type of plant.
Result: Incorrect
Sentence: Generally, a roof is above a floor.
Result: Correct
Sentence: The sky on Earth is blue.
Result: Correct
Sentence: Some dogs are smaller than cats.
Result:
It incorrectly responds with Incorrect.
But when we ask it to show its work:
Classify each sentence as logically correct or incorrect.
Sentence: Dogs are a type of plant.
Analysis: Dogs are animals, not plants.
Result: Incorrect
Sentence: Generally, a roof is above a floor.
Analysis: Ignoring oddly-structured buildings, roofs go above floors.
Result: Correct
Sentence: The sky on Earth is blue.
Analysis: Due to Raleigh scattering, the sky on Earth appears blue.
Result: Correct
Sentence: Some dogs are smaller than cats.
Analysis:
We get back:
Some dogs are smaller than some cats.
Result: Correct
That’s it. Ask the model to show its work and its reasoning is much better.
Matt Brockman has explored this idea using the WIC benchmark.
Do you have more examples of this phenomenon as well? Please let me know on Twitter!